
The Uncanny Valley is something that we have all dealt with and/or thought about in computer graphics. It has become a sort of bogeyman used to scare CG artists and graphics programmers in the same way that monsters under the bed scare little children. “Don’t do that or the Uncanny Valley will get you!!!!” Like all things that we are irrationally scared of, we can put that fear to ease by really analyzing what it is, where we are, and what we can do about it. The TL/DR version of this post: Solving the Uncanny Valley will not be easy, but we shouldn’t be scared of trying.
What is the Uncanny Valley If you really have not heard of the Uncanny Valley, then do a google search. The short version is that recreating human faces in CG is hard. A human likeness that is unrealistic (or cartoony) is easier to relate to. But as human likenesses get nearly real, they get creepy and hard to relate to. Then once you get real enough then that likeness can be subconsciously accepted. The base image came from wikipedia and the licensing information is at the bottom of this page.
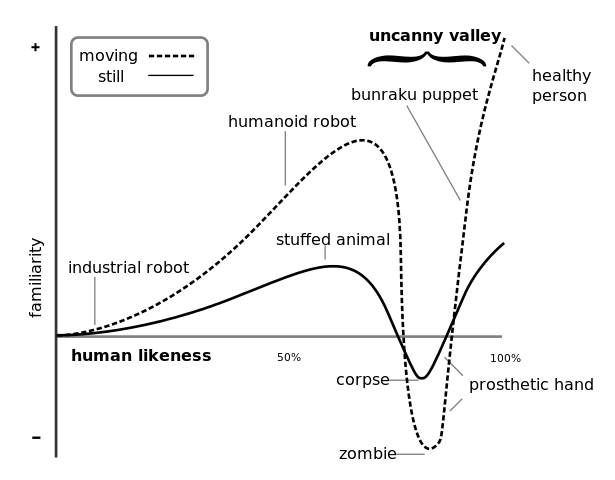
If you have not already, I highly recommend the Wikipedia article: http://en.wikipedia.org/wiki/Uncanny_valley. It has an interesting set of theories about why the Uncanny Valley might exist. Interestingly, the first theory listed is “Mate selection”. I.e. characters in the Uncanny Valley trigger our unconscious mate selection biases because these characters look like they have “low fertility, poor hormonal health, or ineffective immune systems”. As a side note, I’ve always thought that blood flow and other diffuse map changes do not get enough attention. I suppose it makes sense in that someone with no blood flow in their face probably has something very, very wrong with their immune system!
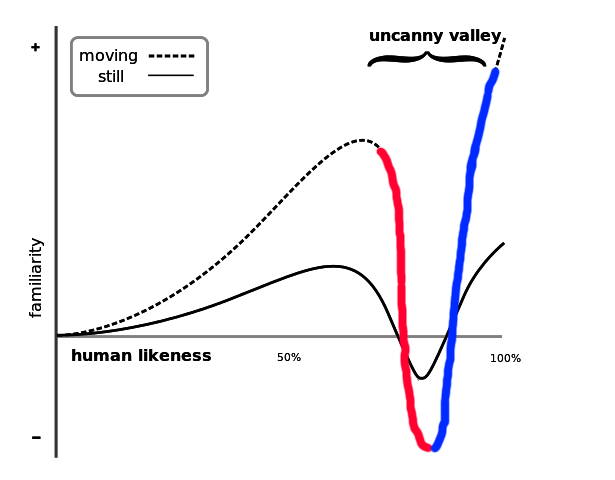
Where is the bottom? While we talk about the Uncanny Valley as something that we should be afraid of, it seems like no one ever talks about where we actually are.
The chart below splits the valley into two sides, the descent and the ascent. If we are on the left side (red), as we get more real we are going deeper and deeper into the horrors of the uncanny valley. In this section, everything that we do to make the characters look “better” will actually make the characters less relatable. We should make games better by giving up, going back, and looking more cartoony.
Then again, if we are on the ascent side (blue) then we have already bottomed out. We have already created the worst, creepiest, most unrelatable characters possible. To make our game look better we need to slowly and agonizingly increase the quality of our characters. But the goal is straightforward: We can make characters look better by making them look better. Simple, right? On this side, we have passed the days of “make it look worse to make it look better”.
In my opinion, video games in the top end graphically are somewhere on the ascending side. It seems like we really hit the bottom of the Uncanny Valley in the early Xbox 360/PS3 generation. Those games had the creepiest, most uncanny characters.
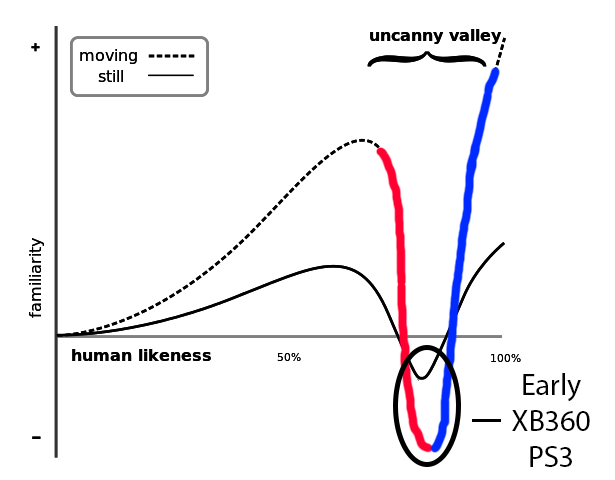
Since then we have been climbing our way up. I would put the best-looking XB1 and PS4 games somewhere in this area:
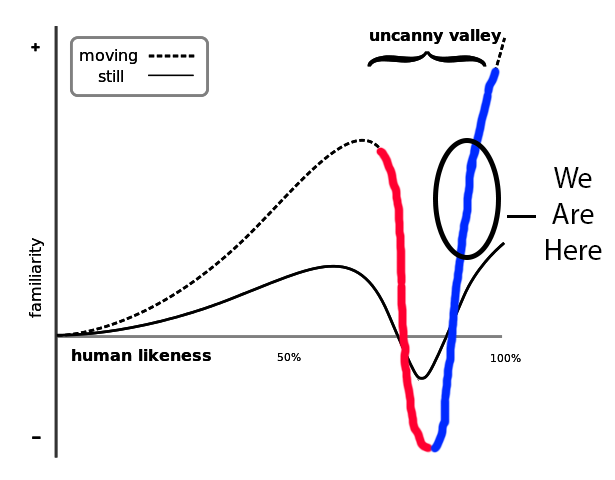
It is hard to say exactly where we are. But we are definitely going the right direction. There is still much work to do, but in my opinion we are much closer to the top of the valley than we are to the bottom.
How far do we have to go? The other interesting question about the Uncanny Valley is “How far is good enough?”. How realistic do characters need to be to become non-creepy? Do they need to be indistinguishable from reality? In my opinion, no.
I have linked to this video before, and I will link to it again. It’s from an artist named Lukáš Hajka who created a DIY Ucap system. You can see images of how it was made on the Crossing the uncanny valley WIP thread over at cgfeedback.com. He also has a tumblr page showcasing his other work.
The idea is pretty simple: You capture video of your talent and solve for textures as well as the model. Then when you play it back, you animate the diffuse map on the face. Note that it was called UCap (for Universal Capture) but these days everyone refers to the concept as 4D Capture so I will stick with that terminology.
To me, this footage crosses the Uncanny Valley. It is definitely not “Photoreal”. You can tell that it is not perfect. The rendering is just the Maya viewport with no shading. But somehow it retains that essence of the person.
What I like about this video is that it shows the purity of the algorithm. There is no lighting. No normal maps. No AO. No skin shading. Just a skinned mesh with an animated diffuse map on top of it. There are similar videos that I’ve seen which were not publicly released and have been lost to time.
There are quite a few examples of similar approaches.
- There is the original work on the Matrix sequels which was the first well-known successful commercial use of 4D data (that I am aware of). If you know of an earlier use, please let me know. Here is an awesome making of video, and you really should watch the whole thing: Universal Capture System (UCap) Reel. The Siggraph sketches are on George Borshukov's webpage: www.plunk.org/~gdb/. It is hard to believe that this data is 12 years old!
- After the Matrix sequels, George Borshukov led a team at EA (which I was on) to apply the same technique in realtime. Here is the best video that I could find (from the 2006 Playstation E3 Press Conference). www.youtube.com/watch?v=DZuMMevcjHo. The chapter in GPU Gems 3 is still online: http.developer.nvidia.com/GPUGems3/gpugems3_ch15.html.
- LA Noire used a similar technology (powered by Depth Analysis, which does not seem to exist any more). You have surely already seen it but here is the tech trailer: LA Noire - Tech Trailer
- Dimensional Imaging (www.di4d.com) provides tools and processing if you want to go this route. They also generously provide sample data: www.di4d.com/sample-data/. They have a long list of games, movies, and trailers which used their technology. But it is unclear how the data was actually used for each application.
Of course there are many reasons why this kind of data is hard to work with and/or prohibitively expensive, but that is not the point. There is something going on in that diffuse map that tricks our brain into accepting it. We need to understand why 4D data looks so good, and apply those learnings to our facial rigs. To me, the answer is simple: We need better animation in our diffuse maps. Unfortunately it is hard to conclusively know exactly what is happening because of baked-in lighting and UV sliding. For example, if the UVs are sliding, it means that the projection of the diffuse map is compensating for the inaccuracy of the geometry, and we should fix the problem with better geometry. But if the diffuse map is stable but changing color, it means that there are color changes that we are missing. Then again if those color changes are due to baked in lighting then the real problem might be the geometry or skin shading. Whatever it is, we need to understand it.
Conclusions. So my main point is simple: We are missing something, but we should be able to figure this out. Using the current techniques for facial animation (bones + wrinkle maps + blendshapes) is not enough. Simply doing more of the same (more bones, more wrinkles, and more blendshapes) will not get us there. We need to do something different. And given the information that we have and the high quality capture solutions available to use, we should be able to figure out what that something is.
Most importantly, we can do this! I truly believe we can make realtime rigs that cross the Uncanny Valley. But it will take hard work, dedication, and a very thorough analysis of reference.
Images Licensing: All Uncanny Valley images on this page are derived from the image provided by Masahiro Mori and Karl MacDorman at http://www.androidscience.com/theuncannyvalley/proceedings2005/uncannyvalley.html and are licensed under the GNU Free Documentation License, Version 1.2.
comments powered by Disqus